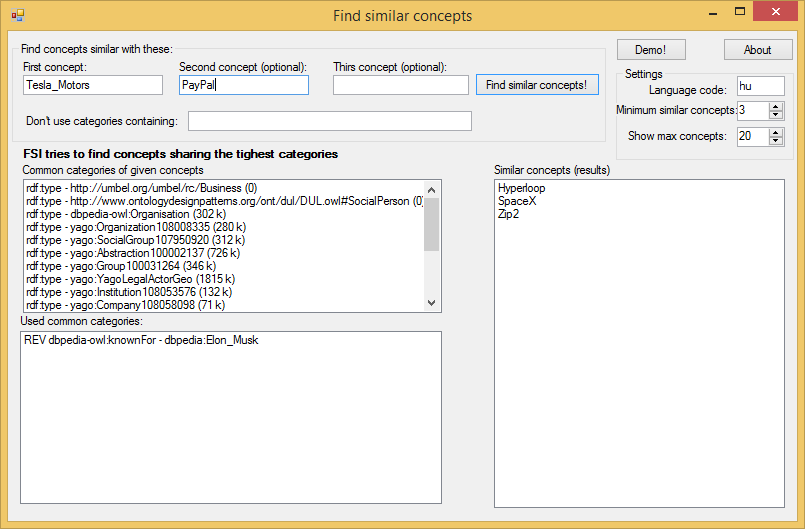
Enter Tesla Motors and PayPal (works of Elon Musk), the software will list Hyperloop and SpaceX as similar concepts. Cool! And you can do it with concepts in any topic!
Introduction
In my childhood I was amazed when I saw Excel completing simple lists: 1-2-3 with 4, or Monday-Tuesday with Wednesday. How many type of series could it extend? Probably not that much, as these had to be programmed one-by-one, or at least type-by-type.
I leave the completion of numeric lists to Excel or LibreOffice, but how about extending any other list with publicly knowledge? Would it be difficult to quickly list all the kings of a country? Or to get the name of the drummer of a band if you remember just the vocalist and guitarist? Or listing all bridges of a city, remembering only two of them? Probably most of you could gather it from the internet. However, if you search for similar type of historical figures from different countries, probably you won’t find lists for this.
I’ve written a program, which tries to list similar concepts to some entered by the user. The results are not ordered (like in Excel), but in much-much wider area. Cars, food, cities, wars, just like anything which is on Wikipedia. Yes, indirectly I’m using Wikipedia’s data for this, more exactly the database at DBpedia.
How it works? 1. Getting data from DBpedia
Working with these available world-representations is important, because they include a huge amount of knowledge, which is not possible to gather and format at home.
These huge datasets are not practical, however possible to download, but we can freely access the API (an open access point) of DBpedia, so an internet-connection is enough to reach allllll data.
Check a page at dbpedia: http://dbpedia.org/page/Matthias_Corvinus
The available data is highly similar to that of Wikipedia, the big difference is that dbpedia stores them in key-value pairs, while – as you know – Wikipedia displays mostly text in paragraphs, which is not easy to understand for the PC. To find all people born in Kaposvár, we just have to run a sparql-query on dbpedia:
select distinct ?Concept where {?Concept dbpprop:birthPlace dbpedia:Kaposvár }
… yeah to see that they can’t handle letters outside of English alphabet. Anyway, with Eger it’s okay.
To get the same information from the text of Wikipedia is much harder, there’s no dedicated keyword/column for this. You can be lucky if it’s in the right-side box, and you don’t have to do natural language processing to get it from the text, which can be of any language 🙂
How it works? 2. Determining common categories
As you could see on the dbpedia page of Matthias, we have a ton of key-value pairs (I call these categories) for all pages. To find similar concepts, we need to find the common key-value pairs of the given concept (eg. Matthias and I. Stephen -> both have key ‘dcterms:subject’, value ‘category:Hungarian_monarchs’) and than query concepts with same categories (listing all Hungarian_monarchs: http://dbpedia.org/page/Category:Hungarian_monarchs).
As shown above, dbpedia returns the results as an answer to an sql-like query, so parsing is not difficult. Finding the common key-value pairs in two pages is programmatically easy, than running a query to list other concepts with these common key-value pairs is also quick – we already have similar concepts!
Two input concepts can have, and generally do have a lot of common categories. This makes possible to find really small categories: finding similar concepts to Shakespeare and Cervantes shows they are not only sharing the ‘dramatist’ category, but they died in the same year! Listing all dramatist of history wouldn’t help us, but with other matching properties we can find more similar results.
How it works? 3. Helping the user to find the record in database
The title of dbpedia pages are written differently from how the user enters it on the GUI. My program tries to locate the page the user wanted to target, it uses the following techniques:
1. Spaces are converted underscores: Los Angeles -> Los_Angeles
2. Disambiguate options are offered to the user to choose: the page Table contains links to 10 different pages. Read from property: dbpedia-owl:wikiPageDisambiguates
3. Redirections are automatically followed: Sour cherry -> Prunus_cerasus. Read from property: dbpedia-owl:wikiPageRedirects
4. More freedom was added by letting the user to enter the word in any language. If I enter ‘Körte’, for which I won’t have any results with the techniques above, the program will try to find any concept in the database which has a ‘sameAs’ link to the Hungarian ‘Körte’. If the English ‘Pear’ page has a note that it is ‘same’ with the Hungarian ‘Körte’ page, that the software will load the ‘Pear’ page, which is perfect for the user. The user can set his languageCode on GUI.
How it works? 4. Limiting common categories
Often we have so many common categories, that dbpedia’s sparql access point fails to answer the query. I had to choose somehow the categories to keep.
1. I query the total number of concepts in the database for which each category is set. I simply ignore categories occuring too often: eg. the category ‘Organism’ is a common category for any two historical figure, but absolutely useless.
2. I have an other list of categories which are always ignored: mostly values containing numerical data. The user won’t be happy to find similar cities based on the ‘April Low temperature’, rather historical or political properties. Also skipped parameters: precipitation data, two other temperature data, UTC offset, chemical data of fruits (categories ending with Mg).
3. If the occurence of a category is too low in the database, it is also a problem. How? What if we enter the name of two Zulu scientists who published in Nature, and assume there are no more people like them in this sense? If the program would find the common category ‘Scientists_with_Zulu_origin’, we wouldn’t have any results except the two input! Instead, we let the user know, that we skipped this category and use just others (zulu, 19. century people, famous_zulus). So common categories which contain only the input concepts are skipped. Plus, the user may set, that he wants to see minimum 4 similar concepts, in this case all categories are skipped which have less then 4 + 2 = 6 concepts in the database. As the chosen categories are changed, we may have completely different results if we want to see 4 or 6 similar concepts. Both group is valid, but one would list for example famous musician Zulus, other the first known zulu leaders.
4. If we dropped the numeric, the really common and the too rare categories, but we still have too much, we have to ignore some valuable categories also. As we want to find similar concepts, we will drop the most common categories. For example we will drop the ‘african_people’ category (with 5000 occurences) and keep the zulu_people (50), otherwise the results would be not so similar to the input concepts. We are repeating this until we have maximum 12 common categories AND we have minimum 5 (or user determined) results.
How it works? 5. Translating results
The results are page titles, which are not every time easy to understand, for example, as above mentioned, the sour cherry is stored with it’s Latin name. Also, there’s opportunity to translate results to an other language, set by the 2-char languageCode on GUI. Translating the result uses the following techniques:
1. Sometimes the key ‘http://www.w3.org/2000/01/rdf-schema#label’ has multiple values for different languages – it’s the easiest.
2. If not, that the ‘sameAs’ links are scanned for other language pages based on the languageCode. It’s like on Wikipedia: you can find other language version of the same page and see the ‘translation’ in the URL.
3) If not, the first method is used with English – still better than the Latin name 🙂
4. If not, the page title is displayed, it is not a false title after all.
Results
What are the results? A good feeling that I could make it, than lot of hours playing with finding interesting similarities and making further improvements. This is a toy now, but I’m sure it will be important in the following decades to show the software a world-representation, and it was a good practice. Have you heard about the Turing test where a software should be “intelligent” enough to chat with a human without uncovering itself? To have a conversation, you have to have representation about the world, to know relation of concepts, which is partly done now. If the conversation contains some concepts, it is now easy to list similars, and ask “Do you know X?”, “I like Y too” which definetly seems to be an intelligent answer.
Currently the software handles the same way all key-value pairs (categories), the next level may be to use them more intelligently. For this I have to build in the knowledge that what the keys are meaning (eg. dbpprop:birthPlace), and how to use them.
I would be happy to have any feedback! About the article, the software, or if you found an interesting query.
If you worked with dotNetRdf: could you query categories containing hypen (-) or accented letters (see above, Kaposvár)?
Download here
Binaries for Windows – push “Demo!” to see how it works.
C# Source is available upon request
Wow! Interesting!
Are there possibility to connect paralell to more public databases?
Even may the article be published on professional forums!
Dear Jenő 🙂
Thank you!
Currently the program handles only one database, but it could join data from different sources. Actually this dataset already contains data from wikipedia, YAGO, w3.org, but they are already joined. The data contains identifiers, which makes it easier to connect it to other DBs, for example we could show images to results easily with querying pictures from imagenet.
I’ve already posted my page on reddit, and made contact with some foreign programmers.
Have a nice day 🙂 Marci